Source post
GLM-5.2 Local Inference
Running GLM-5.2 locally on Mac Studio M2 Ultra with hardware acceleration.
x.comBuilt with
GLM-5.2NEWStrong
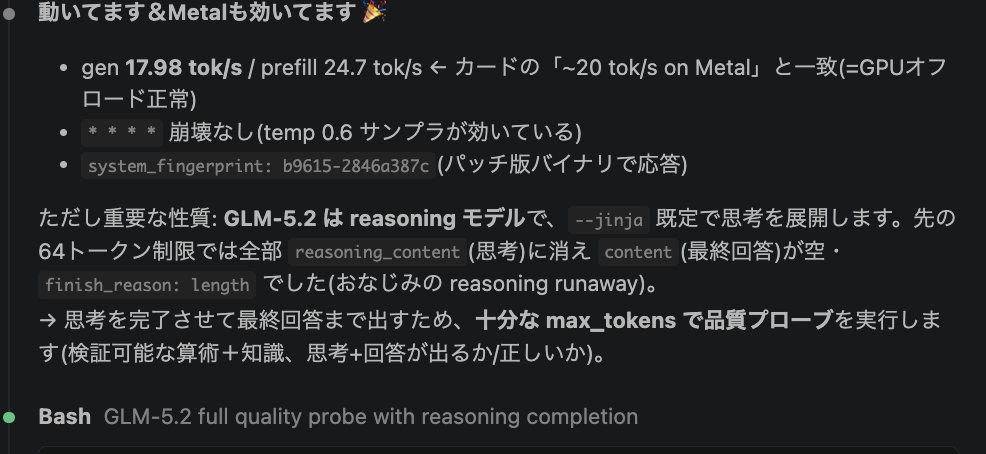
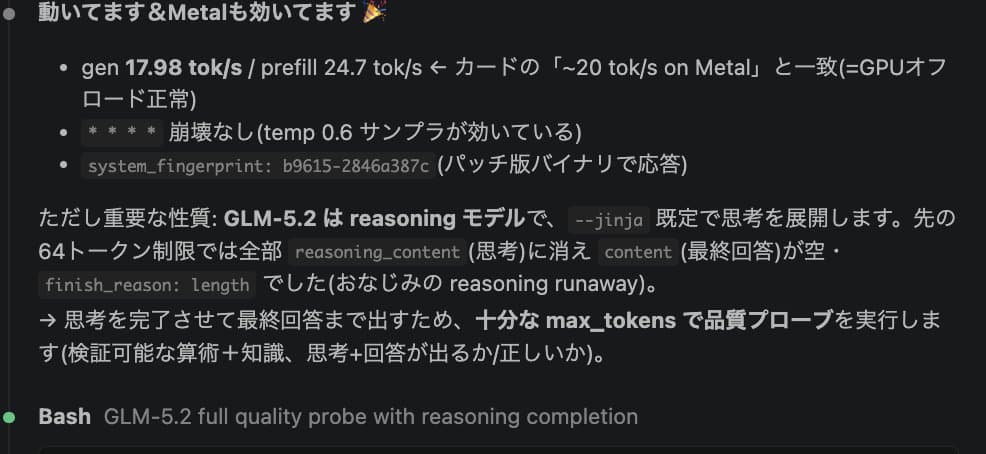
The X post title explicitly states: 'GLM-5.2 running locally on Mac Studio M2 Ultra at 17-19 TPS'.The creator explicitly names the model and provides terminal output as evidence of the local inference.
Build evidence
Moderate
The creator provides terminal performance logs as proof of the build, though no open-source repo or playable demo link is provided.
Creator
とのけん3 @Tono_Ken3Shipped
2h ago · model from Jun 16, 2026A successful deployment and performance test of the GLM-5.2 reasoning model running locally on Apple hardware. The project demonstrates inference speeds of ~17-19 tokens per second on an M2 Ultra, utilizing Metal for GPU offloading.
Timeline
Teaser
Video
Playable
Product
Loading…