Built with
GLM-5.2NEWStrong
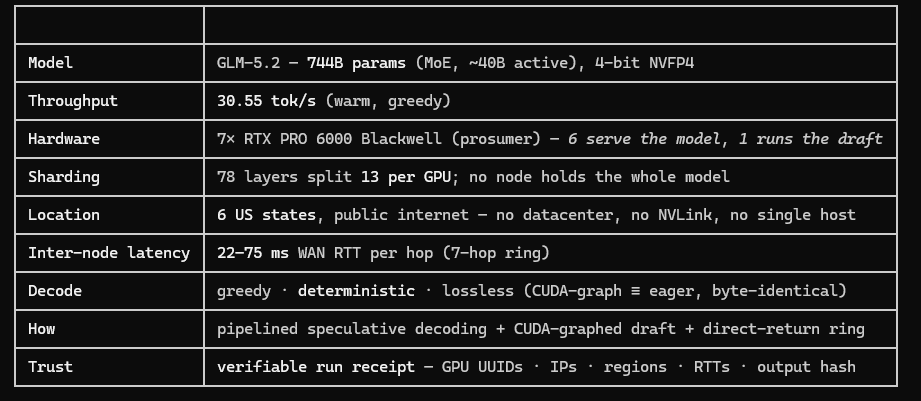
The X post and repository README explicitly mention using GLM-5.2 for 744B parameter inference.The creator provides explicit performance benchmarks and verifiable receipts for GLM-5.2 runs.
Build evidence
Strong
This is a functional code repository with detailed architecture documentation, research logs, and verifiable performance receipts.
Shipped
2h ago · model from Jun 16, 2026Shard is an inference engine that enables distributed LLM serving by splitting model layers across heterogeneous GPUs on different networks. It overcomes WAN latency bottlenecks through techniques like pipelined speculative decoding and CUDA-graphed draft models, allowing large models like GLM-5.2 to run effectively over the open internet.
Source post
Timeline
Teaser
Video
Playable
Product
Loading…
Media & coverage
sourced from 1 post